مقاله و ترجمه : بررسی الگوریتم های خوشه بندی جریان های داده ادامه مطلب »
مقاله و ترجمه : بررسی الگوریتم های خوشه بندی جریان های داده
مقاله و ترجمه : بررسی الگوریتم های خوشه بندی جریان های داده ادامه مطلب »

سفارش ترجمه متون انگلیسی، ترجمه مقاله، سفارش ترجمه مقاله، ترجمه متن، ترجمه کتاب و نگارش پایان نامه از دیگر خدماتی هستند که توسط سایت ما ارائه و پشتیبانی می شوند. جهت سفارش ترجمه با سرپرست تیم مترجم سایت ما تماس بگیرید. سرپرست تیم ترجمه: مهندس محمد علایی ایمیل: Translate@Tnt3.ir تلفن همراه: 09192164907 @ChiefTranslator با توجه به آن که امروزه اکثر دانشجویان ... ادامه مطلب »
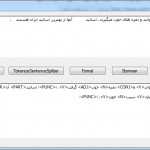
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی در این کد که به زبان سی شارپ نوشته شده است چگونگی استفاده از کتابخانه های ابزارهای پردازش متن فارسی زیر آورده شده است: – نرمالسازی متون فارسی – Normalizer – تشخیص جملات – Sentence Spliter – تشخیص کلمات – Tokenizer – ریشه یابی کلمات – Stemmer – برچسب زنی نحوی کلمات ... ادامه مطلب »

امروزه گسترش فعالیتهای بازرگانی، جهانی شدن و تغییرات وسیع تکنولوژیک در محیط سازمانها باعث گردیده که آنها برای حفظ بقاء و مزایای رقابتی خود از انعطاف پذیری لازم برخوردار باشند لازمه انعطاف پذیری تغییرات سریع است و تغییرات سریع بدون داشتن اطلاعات امکان پذیر نیست، در نتیجه اطلاعات که به عنوان یک منبع بسیار پر ارزش در کنار سایر عوامل ... ادامه مطلب »
عوامل موفقیت و شکست پروژه های IT در سازمانها ادامه مطلب »
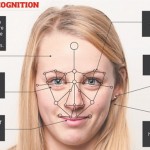
در این فصل، تعدادی از روش های بازشناسی چهره که از ساختارهای تجمعی استفاده می کنند، مورد بررسی قرار گیرند. بررسی این روش ها از یک سو ما را با کارهای انجام گرفته در این زمینه آشنا می کند. یک ساختار تجمعی، در حالت کلی چندین طبقه بند مستقل و یک مکانیزم جهت ترکیب نمودن خروجی این طبقه بندها می ... ادامه مطلب »

مقدمه بازشناسی چهره در سالیان اخیر بسیار مورد توجه قرار گرفته است تا بدانجا که بازشناسی چهره را به یکی از اصلی ترین زمینه های تحقیقاتی در بینایی ماشین، الگوشناسی و یادگیری ماشین تبدیل کرده است. فرایند بازشناسی چهره به صورت کلی به دو قسمت مجزا تقسیم بندی می گردد. یافتن چهره و شناسایی چهره . در فرآیند یافتن چهره، ... ادامه مطلب »
بررسی چند روش بازشناسی مبتنی بر ساختارهای تجمعی ادامه مطلب »
بازشناسی چهره و روش های آن ادامه مطلب »

الگوریتم های یادگیری تجمعی [Fre 1997, Mei 2003, Hay 1998] که ماشین های مشاور نیز نامیده می شوند، یک دسته از الگوریتم های یادگیری به شیوه با سرپرست هستند. این روش ها از تقسیم و حل استفاده می کنند. در روش های مبتنی بر تقسیم و حل یک کار بزرگ به تعدادی کار کوچک شکسته می شود. سپس هر کار ... ادامه مطلب »
الگوریتم های یادگیری تجمعی ادامه مطلب »

کد داده: D3940825a | ثبت در مرجع: ۲۵ آبان ۱۳۹۴ | تعداد بازدید: ۲۸۰ «فااسپل» متشکل از دو ﻣﺠﻤﻮﻋﻪ ﺩﺍﺩﻩ ﺑﺮﺍی ﺍﺭﺯﯾﺎﺑﯽ ﺭوﺵهای خطایابی املایی است. گروه اول شامل خطاهای معمول است که از دانشآموزان مدارس و همچنین خطاهای املایی در هنگام تایپ فارسی جمعآوری شدهاند. این گروه شامل ۵۵۰۰ خطا و کلمهٔ تصحیحشده است. گروه دوم شامل ۸۰۰ جفت ... ادامه مطلب »
کد داده: D3940531a | ثبت در مرجع: ۳۱ مرداد ۱۳۹۴ | تعداد بازدید: ۲۹۵ پیکره حاضر که با هدف ارزیابی سامانههای تقلبیاب تهیه شده است مشتمل بر بیش از ۱۵۰۰ سند فارسی از ویکیپدیا است که ۴۱۱ نمونه تقلب در آنها گنجانده شده است. در قسمتهای حاوی تقلب فرایندهایی چون جابجایی کلمات، حذف و اضافه نمودن کلمات و جایگزین نمودن ... ادامه مطلب »
کد داده: D3930615a | ثبت در مرجع: ۱۵ شهریور ۱۳۹۳ | تعداد بازدید: ۲۱۵۹ پیکره «پاسخ» اولین پیکره متنی برای ارزیابی خلاصهسازی تکسندی و خلاصهسازی چندسندی است که توسط آزمایشگاه فناوری وب دانشگاه فردوسی مشهد و با همکاری سازمان فناوری اطلاعات ایران تولید گردیده. این پیکره مشتمل بر دو مجموعه تکسندی و چندسندی است. در تولید این مجموعه سعی شده ... ادامه مطلب »
کد داده: D3921014a | ثبت در مرجع: ۱۴ دی ۱۳۹۲ | تعداد بازدید: ۲۴۹۵ پایگاه دادههای زبان فارسی مجموعهای است از متون مختلف فارسی که بخشی از آن دارای نشانهگذاریهایی از جمله شناسنامه متن، برچسبهای دستوری، آوایی، ریشهای و معنایی است. این دادگان که در پژوهشگاه علوم انسانی و مطالعات فرهنگی تهیه شده است مجهز به نرمافزارهای اختصاصی جستجو، تقطیع ... ادامه مطلب »
کد داده: D3911203a | ثبت در مرجع: ۰۵ اسفند ۱۳۹۱ | تعداد بازدید: ۱۸۹۰ دادگان گفتاری حاضر شامل حدود ۵۸۰۰ فایل صوتی هجاهای زبان فارسی است که توسط پژوهشکده پردازش هوشمند علائم برای یک برنامه بازسازی گفتار فارسی از نوع بازسازی گفتار به شیوه همگذاری طراحی شده است. بخش اعظم هجاها از صورت واجنویسیشده دادگان بزرگ زبان فارسی گفتاری «فارسدات بزرگ» ... ادامه مطلب »
