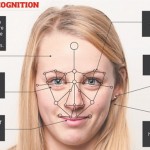
در این فصل، تعدادی از روش های بازشناسی چهره که از ساختارهای تجمعی استفاده می کنند، مورد بررسی قرار گیرند. بررسی این روش ها از یک سو ما را با کارهای انجام گرفته در این زمینه آشنا می کند. یک ساختار تجمعی، در حالت کلی چندین طبقه بند مستقل و یک مکانیزم جهت ترکیب نمودن خروجی این طبقه بندها می ... ادامه مطلب »
بازشناسی مبتنی بر ساختارهای تجمعی